병렬 스트림
병렬 스트림
스레드 풀 사용
- 1~8을 병렬로 더하는 프로그램
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
public class ParallelMain3 {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 스레드 풀을 준비한다.
ExecutorService es = Executors.newFixedThreadPool(2);
long startTime = System.currentTimeMillis();
// 1. Fork 작업을 분할한다.
SumTask task1 = new SumTask(1, 4);
SumTask task2 = new SumTask(5, 8);
// 2. 분할한 작업을 처리한다.
Future<Integer> future1 = es.submit(task1);
Future<Integer> future2 = es.submit(task2);
// 3. join - 처리한 결과를 합친다. get: 결과가 나올 때 까지 대기한다.
Integer result1 = future1.get();
Integer result2 = future2.get();
log("main 스레드 대기 완료");
int sum = result1 + result2;
long endTime = System.currentTimeMillis();
log("time: " + (endTime - startTime) + "ms, sum: " + sum);
es.close();
}
static class SumTask implements Callable<Integer> {
int startValue;
int endValue;
public SumTask(int startValue, int endValue) {
this.startValue = startValue;
this.endValue = endValue;
}
@Override
public Integer call() {
log("작업 시작");
int sum = 0;
for (int i = startValue; i <= endValue; i++) {
int calculated = HeavyJob.heavyTask(i);
sum += calculated;
}
log("작업 완료 result = " + sum);
return sum;
}
}
}
Fork/Join 패턴
분할(Fork) → 처리(Execute) → 모음(Join)의 단계로 이루어진 멀티스레딩 패턴을 Fork/Join 패턴이라고 합니다.
Fork/Join 프레임워크
분할 정복(Divide and Conquer) 전략
- 큰 작업(Task)을 작은 단위로 재귀적으로 분할(Fork)
- 각 작은 작업의 결과를 합쳐(Join) 최종 결과를 생성
- 멀티코어 환경에서 작업으 효율적으로 분산 처리
작업 훔치기(Work Stealing) 알고리즘
- 각 스레드는 자신의 작업 큐를 가짐
- 작업이 없는 스레드는 다른 바쁜 스레드의 큐에서 작업을 훔쳐와서 대신 처리
- 부하 균형을 자동으로 조절하여 효울성 향상
주요 클래스
ForkJoinPool
- Fork/Join 작업을 실행하는 특수한
ExecutorService스레드 풀 - 작업 스케줄링 및 스레드 관리를 담당
- 기본적으로 사용 가능한 프로세서 수 만큼 스레드 생성
ForkJoinTask
ForkJoinTask는 Fork/Join 작업의 기본 추상 클래스Future를 구현- 개발자는 주로 다음 두 하위 클래스를 구현해서 사용
RecursiveTask<V>: 결과를 반환하는 작업RecursiveAction: 결과를 반환하지 않는 작업 (void)
RecursivceTask/RecursiceAction의 구현 방법
compute()메서드를 재정의해서 필요한 작업 로직을 작성- 일반적으로 일정 기준(임계값)을 두고 작업 범위가 작으면 직업 처리하고, 클면 작업을 둘로 분할하여 각각 병렬로 처리하도록 구현
fork()/join() 메서드
fork(): 현재 스레드에서 다른 스레드로 작업을 분할하여 보내는 동작join(): 분할된 작업이 끝날 때까지 기다린 후 결과를 가져오는 동작
코드 예시
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
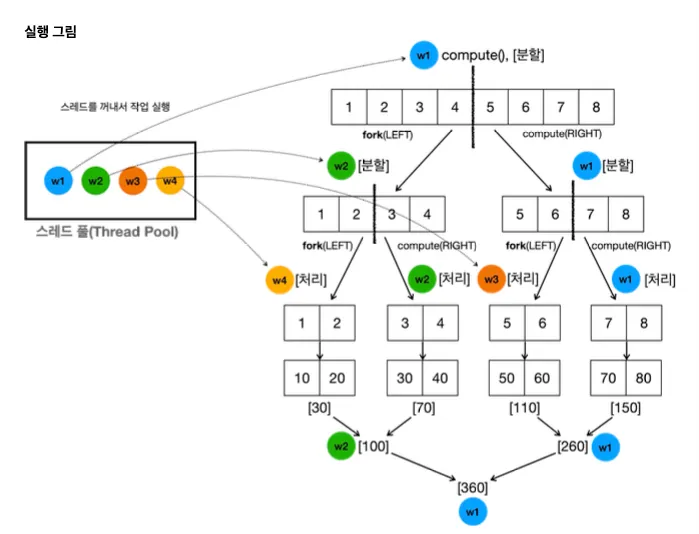
public class SumTask extends RecursiveTask<Integer> {
//private static final int THRESHOLD = 4; // 임계값
private static final int THRESHOLD = 2; // 임계값 변경
private final List<Integer> list;
public SumTask(List<Integer> list) {
this.list = list;
}
@Override
protected Integer compute() {
// 작업 범위가 작으면 직접 계산
if (list.size() <= THRESHOLD) {
log("[처리 시작] " + list);
int sum = list.stream()
.mapToInt(HeavyJob::heavyTask)
.sum();
log("[처리 완료] " + list + " -> sum: " + sum);
return sum;
} else {
// 작업 범위가 크면 반으로 나누어 병렬 처리
int mid = list.size() / 2;
List<Integer> leftList = list.subList(0, mid);
List<Integer> rightList = list.subList(mid, list.size());
log("[분할] " + list + " -> LEFT" + leftList + ", RIGHT" + rightList);
SumTask leftTask = new SumTask(leftList);
SumTask rightTask = new SumTask(rightList);
// 왼쪽 작업은 다른 스레드에서 처리
leftTask.fork();
// 오른쪽 작업은 현재 스레드에서 처리
Integer rightResult = rightTask.compute();//[5 ~ 8] -> 260
// 왼쪽 작업 결과를 기다림
Integer leftResult = leftTask.join();
int joinSum = leftResult + rightResult;
log("LEFT[ + " + leftResult + "] + RIGHT[" + rightResult + "] -> sum:" + joinSum);
return joinSum;
}
}
}
- ForkJoinPool 직접 생성하는 방식
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
public class ForkJoinMain1 {
public static void main(String[] args) {
List<Integer> data = IntStream.rangeClosed(1, 8)
.boxed()
.toList();
log("[생성] " + data);
// ForkJoinPool 생성 및 작업 수행
long startTime = System.currentTimeMillis();
ForkJoinPool pool = new ForkJoinPool(10);
SumTask task = new SumTask(data); // [1 ~ 8]
// 병렬로 합을 구한 후 결과 출력
Integer result = pool.invoke(task);
pool.close();
long endTime = System.currentTimeMillis();
log("time: " + (endTime - startTime) + "ms, sum: " + result);
log("pool: " + pool);
}
}
- ForkJoinPool 공용 풀 사용하는 방식
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
public class ForkJoinMain2 {
public static void main(String[] args) {
int processorCount = Runtime.getRuntime().availableProcessors();
ForkJoinPool commonPool = ForkJoinPool.commonPool();
log("processorCount = " + processorCount + ", commonPool = " + commonPool.getParallelism());
List<Integer> data = IntStream.rangeClosed(1, 8)
.boxed()
.toList();
log("[생성] " + data);
SumTask task = new SumTask(data);
Integer result = task.invoke(); // 공용 풀 사용
log("최종 결과: " + result);
}
}
작업 훔치기
- Fork/Join 풀의 스레드는 각자 자신의 작업 큐를 가짐
- 덕분에 작업을 큐에서 가져가기 위한 스레드간 경합이 줄어듦
- 자신의 작업이 없는 경우, 다른 스레드의 작업 큐에 대기중인 작업을 훔쳐서 대신 처리
Fork/Join 공용 풀
자바 8에 Fork/Join 작업을 위한 공용 풀이라는 개념이 도입되었습니다.
특징
- 시스템 전체에서 공유: 애플리케이션 내에서 단일 인스턴스로 공유
- 자동 생성: 별도로 생성하지 않아도
ForkJoinPool.commonPool()을 통해 접근 할 수 있음 - 편리한 사용: 별도의 풀을 만들지 않아도
RecursiveTask/RecursiveAction을 사용할 때 기본적으로 공용 풀이 사용 됨 - 병렬 스트림 활용: 자바 8의 병렬 스트림은 내부적으로 공용 풀을 사용 함
- 자원 효율성: 여러 곳에서 별도의 풀을 생성하는 대신 공용 풀을 사용함으로써 시스템 자원을 효율적으로 관리할 수 있음
- 병렬 수준 자동 설정: 기본적으로 시스템 가용 프로세서 수에서 1을 뺀 값으로 병렬 수준을 설정
자바 병렬 스트림
.parallel()한 줄 추가하면 병렬 스트림 완성
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
public class ParallelMain4 {
public static void main(String[] args) {
int processorCount = Runtime.getRuntime().availableProcessors();
ForkJoinPool commonPool = ForkJoinPool.commonPool();
log("processorCount = " + processorCount + ", commonPool = " + commonPool.getParallelism());
long startTime = System.currentTimeMillis();
int sum = IntStream.rangeClosed(1, 8)
.parallel() // 추가
.map(HeavyJob::heavyTask)
.reduce(0, (a, b) -> a + b); // sum();
long endTime = System.currentTimeMillis();
log("time: " + (endTime - startTime) + "ms, sum: " + sum);
}
}
병렬 스트림 주의점
- CPU바운드 작업에만 사용하는 것을 권장
- I/O 바운드 작업은 오랜 대기 시간이 발생하므로, 제한된 스레드만 쓰는 Fork/Join 공용 풀과 궁합이 좋지 않음
- 서버 환경에서 여러 요청이 동시에 병렬 스트림을 사용하면 공용 풀이 빠르게 포화되어 전체 성능이 저하 될 수 있음
별도의 풀 사용
- I/O 바운드 작업 처럼 대기가 긴 경우에는 전용 스레드 풀을 만들어 사용하는 것을 권장
- 스레드 풀의 크기, 스레드 생성 정책, 큐 타입 등을 상황에 맞게 튜닝할 수 있어 확장성과 안정성이 높아짐
CompletableFuture 사용 시 주의 상황
CompletableFuture를 생성할 때 별도의 스레드를 지정하지 않으면 Fork/Join 공용 풀이 사용 됨- 반드시 커스텀 풀을 지정해서 사용해야 함
1
2
3
4
5
6
7
8
9
10
11
public class CompletableFutureMain {
public static void main(String[] args) throws InterruptedException {
CompletableFuture.runAsync(() -> log("Fork/Join")); // Fork/Join 공용 풀
ExecutorService es = Executors.newFixedThreadPool(100);
CompletableFuture.runAsync(() -> log("Custom Pool"), es); // 별도의 풀
Thread.sleep(100);
es.close();
}
}
참고
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.