해시(Hash) 알고리즘
해시(Hash) 알고리즘
해시 알고리즘을 사용하면 데이터를 찾는 검색 성능을 평균 O(1) 성능으로 끌어올릴 수 있습니다.
Index 사용
배열은 index 위치로 데이터를 찾을 때는 O(1) 성능을 보이지만 검색할 때는 O(n)의 성능을 보여줍니다.
만약 검색도 index를 통해 할 수 있다면 O(1)의 성능으로 끌어올릴 수 있을 것입니다.
데이터 값 자체를 배열의 인덱스와 맞추어 저장

이렇게 하면 값으로 index 조회할 수 있게 됩니다.
단점
이 방식의 치명적인 단점은 메모리가 너무 낭비 된다는 것입니다.
나머지 연산을 통해 해결
나머지 연산(%)을 이용하면 공간도 절약하면서, 넓은 범위의 값을 사용할 수 있도록 할 수 있습니다.
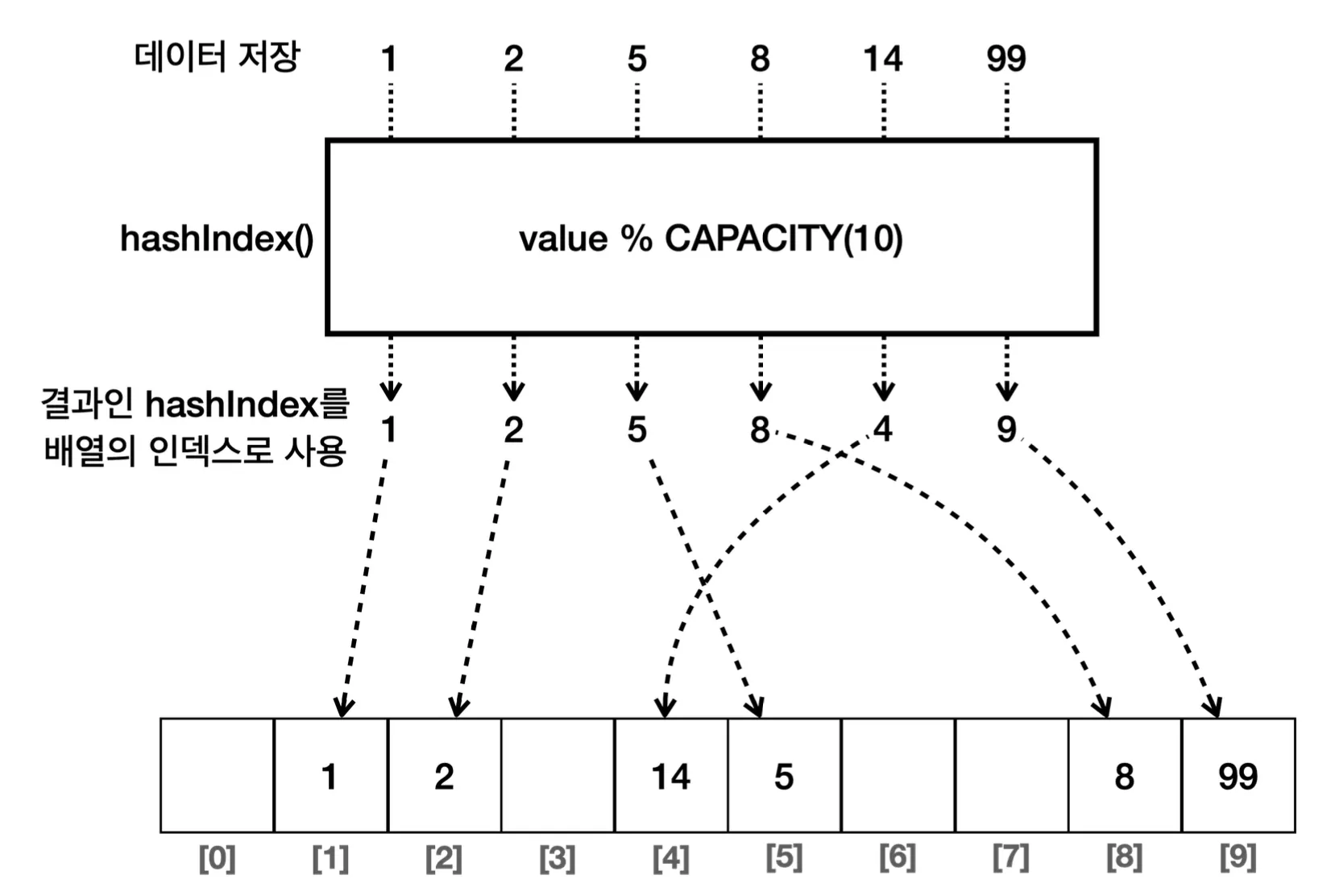
💡 해시 인덱스
배열의 인덱스로 사용할 수 있도록 원래의 값을 계산한 인덱스
해시 충돌
위 방식의 문제는 나머지 연산의 값이 동일하다면 같은 index가 나와 충돌한다는 것입니다.
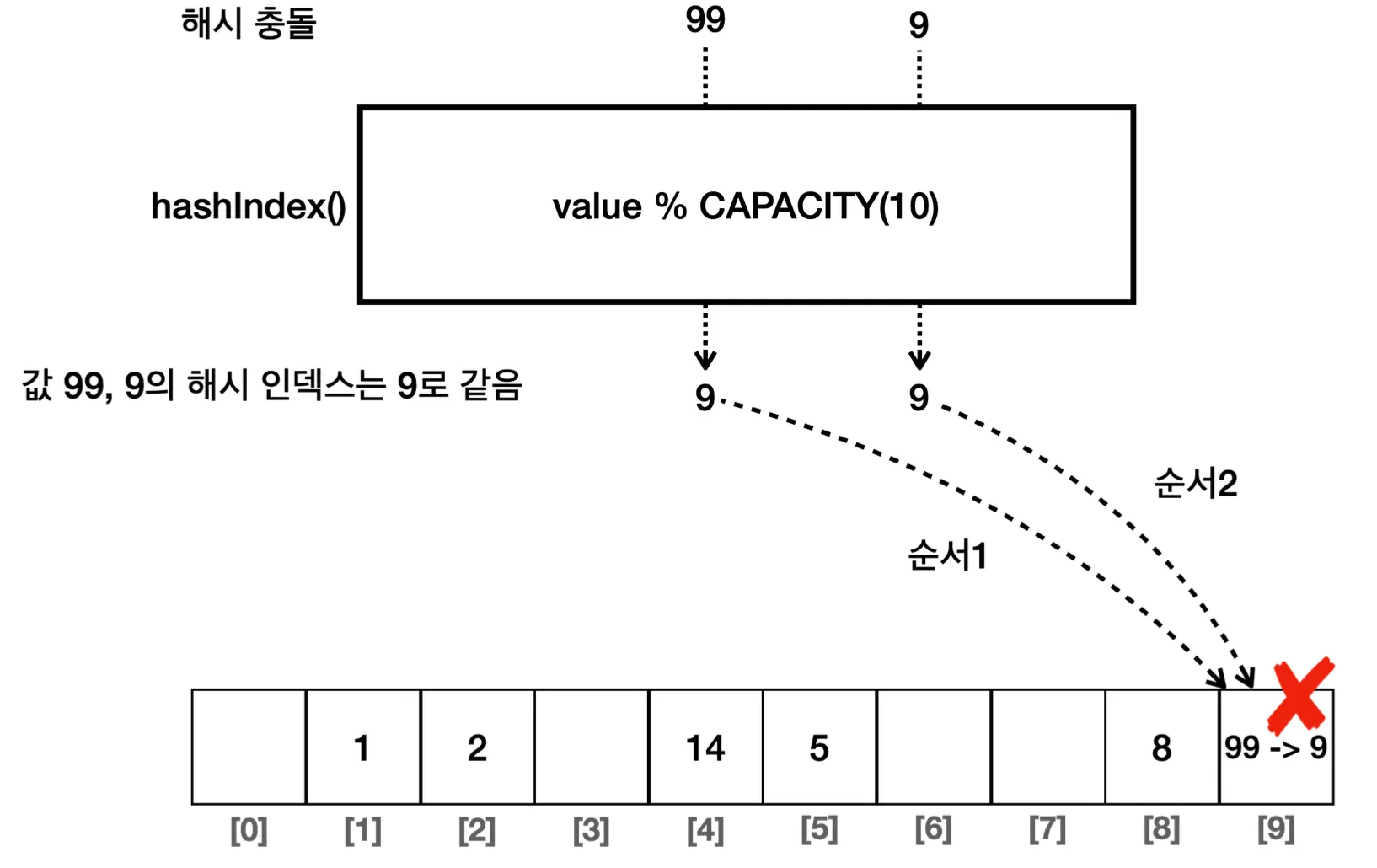
해시 충돌 해결
해시 충돌을 인정하고, 같은 공간에 또 다른 배열을 만들어 저장하도록 하여 이 문제를 해결할 수 있습니다.
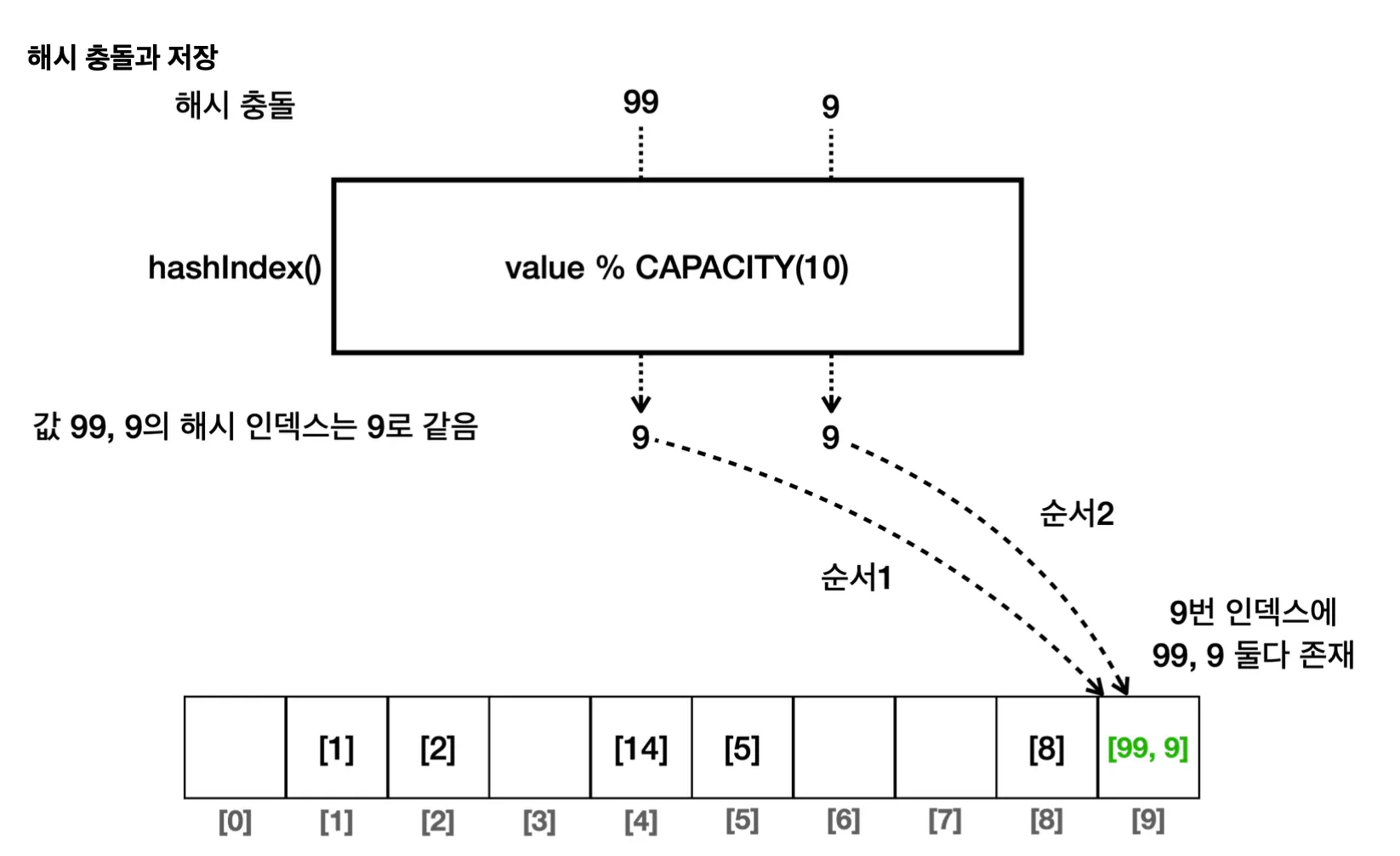
문제
같은 index에 들어있는 요소를 검색할 때 최악의 경우O(n)의 성능을 보입니다. 하지만 해시 충돌이 자주 발생하는 것은 아니므로 평균적으로 O(1)과 비슷한 성능을 보여줍니다.
참고
이 기사는 저작권자의 CC BY 4.0 라이센스를 따릅니다.